AI in Production -- Part 7
Testing AI Features: Reliable Tests for an Unreliable Component
The Problem
You’ve written the AI feature. You want to write tests. You open a new test file and type:
var result = await _ai.SummarizeAsync(document.Body);
Assert.Equal("This document is about...", result);And then you stop. Because that test will fail. Not because the code is wrong — because the model will return different text every time. Different phrasing, different length, maybe a different structure. That’s how language models work. Same input, different output.
So what do you test?

Most teams end up in one of two bad places. Either they don’t test the AI layer at all (“it’s non-deterministic, what’s the point?”) — and they find bugs in production. Or they mock everything so heavily that their tests never touch the real AI behaviour — and they still find bugs in production, just different ones.
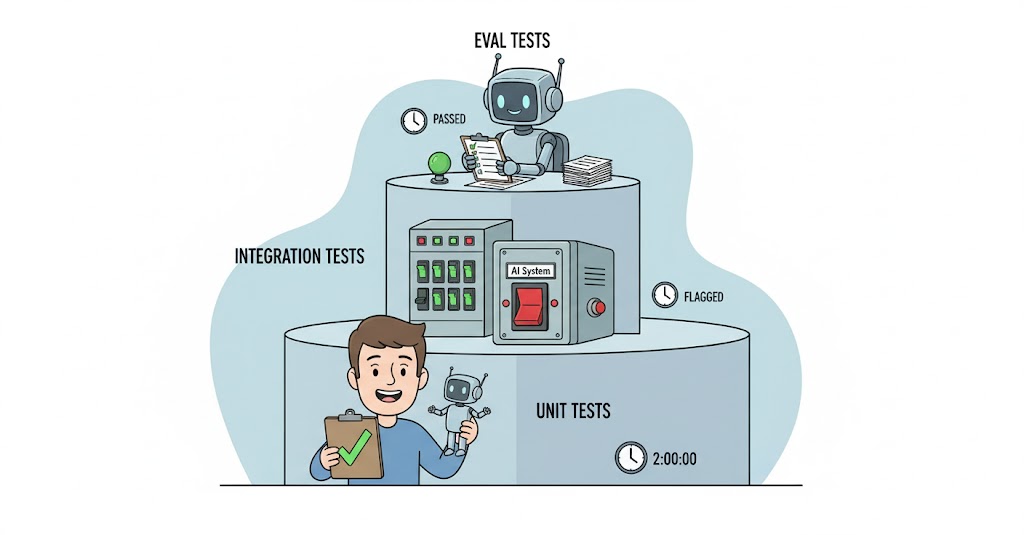
The right answer is three separate layers of testing, each with a different goal:
Layer 1 — Unit tests. Mock the AI entirely. Test your application logic. Does the controller handle a null response correctly? Does the enricher skip already-enriched documents? Does the consent middleware block the right requests? These tests run fast, don’t call any external service, and they cover the code around the AI.
Layer 2 — Integration tests. Test failure paths with fake HTTP handlers. Does the circuit breaker open after 5 failures? Does the fallback return null instead of throwing? These tests validate the resilience behaviour from article 2, without needing a real AI provider.
Layer 3 — Eval tests. Call the real model with a fixed set of inputs. Don’t assert exact output — assert quality criteria. Is the response non-empty? Does it meet a minimum length? Does it follow the expected structure? Does it avoid refusal patterns? These run less frequently, cost real tokens, and catch regressions when the model changes.
Each layer answers a different question. Together, they give you real coverage.
Execute
Layer 1 — Unit tests with a mocked AI service
The interface from article 2 (IAiSummaryService) makes this easy. You can replace the real implementation with a controlled fake.
Using NSubstitute (works with any mocking library):
[Fact]
public async Task GetSummary_WhenAiReturnsNull_ReturnsAiUnavailable()
{
// Arrange
var ai = Substitute.For<IAiSummaryService>();
ai.SummarizeAsync(Arg.Any<string>(), Arg.Any<CancellationToken>())
.Returns((string?)null);
var documents = Substitute.For<IDocumentRepository>();
documents.GetByIdAsync(Arg.Any<Guid>(), Arg.Any<CancellationToken>())
.Returns(new Document { Id = Guid.NewGuid(), Title = "Test", Body = "Body text" });
var controller = new DocumentsController(documents, ai);
// Act
var result = await controller.GetSummary(Guid.NewGuid(), CancellationToken.None);
// Assert
var ok = Assert.IsType<OkObjectResult>(result);
var body = Assert.IsAssignableFrom<dynamic>(ok.Value);
Assert.False((bool)body.AiAvailable);
}
[Fact]
public async Task GetSummary_WhenAiReturnsText_ReturnsSummary()
{
// Arrange
var ai = Substitute.For<IAiSummaryService>();
ai.SummarizeAsync(Arg.Any<string>(), Arg.Any<CancellationToken>())
.Returns("A brief summary of the document.");
var documents = Substitute.For<IDocumentRepository>();
documents.GetByIdAsync(Arg.Any<Guid>(), Arg.Any<CancellationToken>())
.Returns(new Document { Id = Guid.NewGuid(), Title = "Test", Body = "Body text" });
var controller = new DocumentsController(documents, ai);
// Act
var result = await controller.GetSummary(Guid.NewGuid(), CancellationToken.None);
// Assert
var ok = Assert.IsType<OkObjectResult>(result);
var body = Assert.IsAssignableFrom<dynamic>(ok.Value);
Assert.True((bool)body.AiAvailable);
Assert.NotNull(body.Summary);
}These tests never call the AI. They test your code — the controller, the null handling, the response shape. They run in milliseconds.
Layer 2 — Integration tests for failure paths
From article 2, you have an AlwaysFailHandler. Use it to verify the circuit breaker and fallback behaviour work correctly:
public class AlwaysFailHandler : DelegatingHandler
{
protected override Task<HttpResponseMessage> SendAsync(
HttpRequestMessage request,
CancellationToken cancellationToken) =>
Task.FromResult(new HttpResponseMessage(HttpStatusCode.ServiceUnavailable));
}
[Fact]
public async Task SummarizeAsync_WhenProviderReturns503_ReturnsNull()
{
// Arrange
var handler = new AlwaysFailHandler
{
InnerHandler = new HttpClientHandler()
};
var client = new HttpClient(handler) { BaseAddress = new Uri("http://test") };
var logger = NullLogger<AiSummaryService>.Instance;
var service = new AiSummaryService(client, logger);
// Act
var result = await service.SummarizeAsync("some text");
// Assert — must return null, not throw
Assert.Null(result);
}
[Fact]
public async Task SummarizeAsync_WhenCircuitOpens_StopsCallingProvider()
{
// Arrange — trigger enough failures to open the circuit
var callCount = 0;
var countingHandler = new CountingFailHandler(ref callCount);
var client = new HttpClient(countingHandler) { BaseAddress = new Uri("http://test") };
var service = new AiSummaryService(client, NullLogger<AiSummaryService>.Instance);
// Act — exhaust the circuit breaker (MinimumThroughput = 5 from article 2)
for (var i = 0; i < 10; i++)
{
await service.SummarizeAsync("some text");
}
// Assert — circuit opened, later calls don't reach the handler
Assert.True(callCount < 10, "Circuit should have opened before all 10 calls");
}These tests validate that your resilience configuration actually works. A misconfigured circuit breaker (wrong thresholds, missing exception types) would fail here — not in production at 11pm.
Layer 3 — Eval tests against the real model
Eval tests call the real AI. They’re slow and cost tokens, so you run them separately from your normal test suite — on a schedule, or before a release.
The key difference from traditional tests: you don’t assert exact output. You assert quality criteria.
// Mark these as a separate category — don't run in normal CI
[Trait("Category", "Eval")]
public class AiSummaryEvalTests
{
private readonly IAiSummaryService _ai;
public AiSummaryEvalTests()
{
// Real service — reads API key from environment
var client = new HttpClient
{
BaseAddress = new Uri(Environment.GetEnvironmentVariable("AI_BASE_URL")!)
};
client.DefaultRequestHeaders.Add(
"Authorization",
$"Bearer {Environment.GetEnvironmentVariable("AI_API_KEY")}");
_ai = new AiSummaryService(client, NullLogger<AiSummaryService>.Instance);
}
[Theory]
[MemberData(nameof(EvalCases))]
public async Task Summarize_MeetsQualityCriteria(EvalCase eval)
{
// Act
var result = await _ai.SummarizeAsync(eval.Input);
// Assert quality criteria — not exact output
Assert.NotNull(result);
Assert.True(result.Length >= eval.MinLength,
$"Summary too short: {result.Length} chars, expected >= {eval.MinLength}");
Assert.True(result.Length <= eval.MaxLength,
$"Summary too long: {result.Length} chars, expected <= {eval.MaxLength}");
Assert.DoesNotContain("I'm sorry", result, StringComparison.OrdinalIgnoreCase);
Assert.DoesNotContain("I cannot", result, StringComparison.OrdinalIgnoreCase);
// Optional: check that key concepts from the input appear in the summary
foreach (var keyword in eval.ExpectedKeywords)
{
Assert.Contains(keyword, result, StringComparison.OrdinalIgnoreCase);
}
}
public static IEnumerable<object[]> EvalCases() =>
[
[new EvalCase(
Input: "The quarterly report shows revenue growth of 12% driven by enterprise customers. Operating costs increased by 3% due to infrastructure investments. Net margin improved to 18%.",
MinLength: 50,
MaxLength: 300,
ExpectedKeywords: ["revenue", "margin"]
)],
[new EvalCase(
Input: "The system uses a microservices architecture with 14 independent services communicating over gRPC. Each service owns its database. Deployments use blue-green with automatic rollback.",
MinLength: 50,
MaxLength: 300,
ExpectedKeywords: ["microservices", "deployment"]
)]
];
}
public record EvalCase(
string Input,
int MinLength,
int MaxLength,
string[] ExpectedKeywords
);Run eval tests on a schedule — weekly, or before every release. When the provider updates the model, you’ll know immediately if quality dropped. Not from user complaints. From a failing eval.
Keeping eval tests separate
In your CI pipeline:
# .github/workflows/ci.yml
- name: Unit and integration tests
run: dotnet test --filter "Category!=Eval"
# Eval tests run separately — on schedule or manually
- name: Eval tests
if: github.event_name == 'schedule'
run: dotnet test --filter "Category=Eval"
env:
AI_BASE_URL: ${{ secrets.AI_BASE_URL }}
AI_API_KEY: ${{ secrets.AI_API_KEY }}Unit and integration tests run on every push, in seconds. Eval tests run weekly, in minutes, with real API costs.
What good eval criteria look like
The hardest part of eval testing is defining the right criteria. Start simple:
| Criterion | What to check | Code |
|---|---|---|
| Non-empty | Response exists and has content | Assert.NotNull + length check |
| Right length | Not too short (refusal) or too long (verbose) | Min/max bounds |
| No refusal | Model didn’t refuse the request | Check for “I’m sorry”, “I cannot” |
| Key concepts | Important terms from the input appear | Keyword presence |
| Structure | If you expect JSON, it parses correctly | JsonDocument.Parse |
![A quality inspector robot sits at a desk checking AI documents against a rubric: "non-empty ✓", "right length ✓", "no refusals ✓", "keywords present ✓". A rejected pile has documents labeled "I'm sorry" and "[empty]".](/images/eval.jpg)
Don’t try to assert meaning. You can’t. Focus on structure and proxies for quality. If the summary mentions “revenue” when the input was about revenue, that’s a meaningful signal. If it’s 12 characters long, something is wrong.
Checklist
- Do your unit tests mock
IAiSummaryServiceand test the code around the AI? - Do your integration tests verify that null is returned (not thrown) on AI failure?
- Is there a test that opens the circuit breaker and confirms later calls are skipped?
- Do you have eval cases with real inputs and quality criteria (not exact output)?
- Are eval tests separated from your main test suite and run on a schedule?
- Do your eval tests check for refusal patterns and minimum response length?
The goal isn’t 100% coverage of what the model says. It’s confidence that your code handles the AI correctly — and that the AI hasn’t quietly gotten worse.
Before the Next Article
Six articles on specific problems. One article on integrating into real systems. One on testing.
The last article puts it all together. Not another pattern or technique — a production readiness checklist. The questions you answer before any AI feature goes live, covering everything from articles 1 through 7. A single reference you can hand to a team and say: if you can check every box, your AI feature is ready for production.
That’s article 8.
If this series helps you, consider buying me a coffee.
This is article 7 of the AI in Production series. Next: Production Readiness — the complete checklist before your AI feature goes live.
Loading comments...