The Three Ways in the AI Era -- Part 5
SDD, ATLAS, GOTCHA: When to Use What (And When They All Fail)
Four articles in, we have made SDD, ATLAS, and GOTCHA look like magic. Specs fix flow. GOTCHA fixes feedback. Tutor mode fixes learning. Pick the right tool, apply it, ship better code.
That is half the truth. The other half is that none of these frameworks is a silver bullet, and teams that pile all three on without thinking get slower, not faster. This article is the uncomfortable part. Where each framework shines, where each one fails, and what to do when the real bottleneck is not something a framework can fix.
PROBLEM

I worked with a team last year that adopted SDD, ATLAS, and GOTCHA in the same quarter. The founder had read the books. The CTO had seen the conference talks. Everyone was enthusiastic.
Three months later:
- Every PR required a spec, a GOTCHA prompt review, and an ATLAS checklist. Average PR age went from 1 day to 5.
- Devs were spending 20% of their week writing 200-line specs for 10-line CSS changes.
- The repo had 17 different GOTCHA prompts. Half of them contradicted each other. Nobody owned them.
- ATLAS “Architect” ceremonies blocked 3-person sprints every Monday for 90 minutes.
The team was doing “best practice” by the book. Their output collapsed.
I have seen the same pattern at a bank, at a scale-up, and at a consultancy. The frameworks were not the problem. Applying them to every task was the problem.
Gene Kim’s First Way says: small batches. Small doses, too. A framework is a tool, not a religion.
SOLUTION
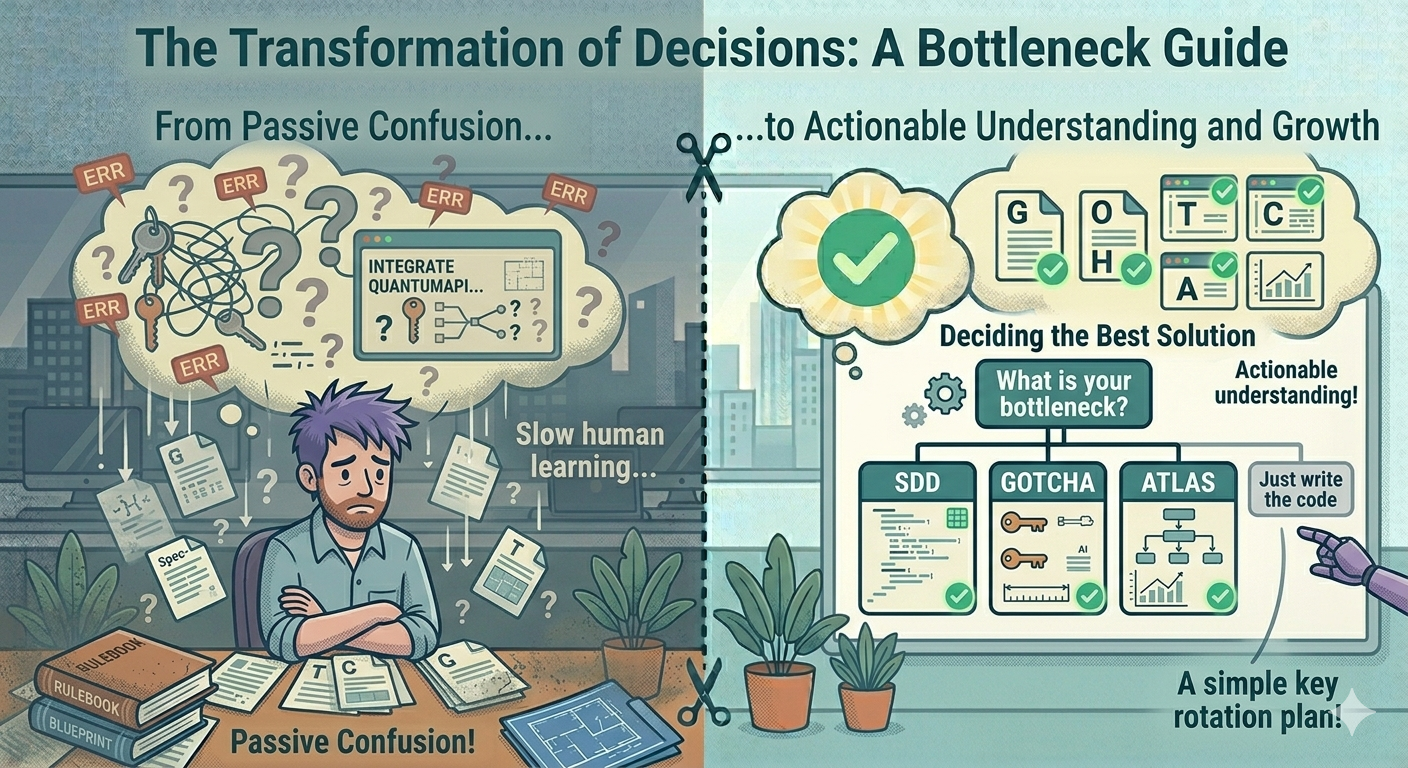
Before adding any framework, ask one question:
What is our actual bottleneck right now?
Not “what could go wrong?”. Not “what do other teams use?”. What is slowing us down, this month, measurably? Answer that first. Then pick the framework that fits. Or none.
Here is the map:
| Bottleneck | SDD | GOTCHA | ATLAS |
|---|---|---|---|
| PRs too big / scope creep | ✅ Primary | ⚠️ Indirect | ⚠️ Architect step helps |
| AI reviewer noise / feedback ignored | ⚠️ Helps set scope | ✅ Primary | ❌ Wrong layer |
| Team not aligned / handoffs drop | ❌ Too narrow | ❌ Too narrow | ✅ Primary |
| Knowledge not sticking (bus factor 0) | ⚠️ Specs help | ✅ Tutor mode + learning notes | ⚠️ Handoff step helps |
| Small team, simple app | ❌ Overkill | ⚠️ Only for repeat tasks | ❌ Overkill |
Three frameworks. Not one. The art is knowing which one.
EXECUTE
SDD — when it shines, when it fails
Shines on:
- Features with clear acceptance criteria
- Compliance-driven work (audits, regulations, security)
- Teams new to AI that need guardrails
- Anything where scope creep is the pattern
Fails on:
- Exploratory spikes — you do not know the answer yet, do not pretend you do
- Bug fixes under 30 minutes
- Tiny refactors
- Pure UI tweaks
Anti-pattern — “Spec ceremony”: writing a 200-line spec with Goals, Non-goals, and Acceptance criteria for a 10-line CSS change. I saw a team waste 20% of their sprint capacity on this before someone finally said “just fix the margin”.
Real case: A fintech team required specs for every PR. Their 2-line bug fix for an off-by-one error took 4 days because the spec had to be reviewed by two seniors, then the code had to be reviewed, then the learning note had to be reviewed. The same bug would have taken 20 minutes without SDD.
GOTCHA — when it shines, when it fails
Shines on:
- Repetitive AI tasks: code review, PR summaries, incident triage, postmortem drafts
- High-stakes domains (security, finance, PQC) where context matters
- Any AI task your team runs more than twice a week
Fails on:
- One-off creative tasks
- Early exploration (“what even are our options?”)
- Ad-hoc pair programming sessions
- Anything where the prompt needs to change every time
Anti-pattern — “Prompt fossilization”: a repo with 17 GOTCHA prompts, half of them contradicting each other, none of them owned. Nobody reads them. The AI follows whichever one it was last pointed at. Output becomes random.
Real case: A consultancy built a GOTCHA library of 23 prompts across their client work. After 6 months, three of the prompts told the AI to “never flag style issues” and two others told it to “always enforce style guides”. Reviews became inconsistent, devs lost trust, the library was scrapped and rebuilt from 4 well-maintained prompts.
ATLAS — when it shines, when it fails
Shines on:
- Large cross-functional initiatives (multiple teams, disciplines)
- Work with real handoffs (backend → frontend → ops)
- Features that span a quarter, not a week
Fails on:
- Individual dev tasks
- Startups with 2-5 engineers (overhead > benefit)
- Short-cycle work where “Architect” takes longer than the task
Anti-pattern — “Checklist theater”: devs tick the ATLAS boxes without thinking. The Architect step is filled with boilerplate. Trace is skipped. Stress-test is “yeah, it compiles”. The ritual exists. The thinking does not.
Real case: A 3-person startup adopted ATLAS after their CTO came back from a conference. Every PR required a full ATLAS write-up including Link, Assemble, and Stress-test. Within a month, PRs had 2-day average age and devs openly mocked the process. They dropped ATLAS entirely. Two years later they brought back only the “Architect” step, for features longer than a sprint.
The uncomfortable truth — all three can fail together

If your real bottleneck is cultural — no trust, no ownership, no learning culture, leadership that punishes mistakes — no framework will fix it.
Frameworks are amplifiers. They make good teams better. They make struggling teams painfully slow and still struggling. SDD on a team that does not trust its devs becomes a gatekeeping mechanism. GOTCHA on a team with no code review culture becomes 17 contradictory prompts. ATLAS on a team that does not talk becomes 90 minutes of silence per week.
The biggest anti-pattern is “Framework tower”: a team using SDD + ATLAS + GOTCHA + DORA + BDD + TDD + DDD + SAFe. Each one was sensible in isolation. Stacked, they ship nothing. I have seen a Series C company spend 6 months doing “process improvement” and ship two features.
If nothing is breaking, do not add a framework. Boredom is not a reason to add process.
How the QuantumAPI team actually uses them

After 3 months, the team from Articles 1-4 stopped following frameworks by the book and started matching them to actual work:
| Task type | What they use | Why |
|---|---|---|
| Feature ≥ 4 hours OR ≥ 5 files | SDD (full spec) | Scope creep was the real pain |
| Small bug fix | Just write the code | SDD overhead > bug impact |
| Any recurring AI task | GOTCHA prompt, versioned in repo | Consistency matters here |
| One-off AI chat | Plain prompt, no GOTCHA | Creativity not reproducibility |
| New feature spanning 2+ teams | ATLAS Architect step only | Alignment without ceremony |
| Sprint-scale work | Skip ATLAS entirely | Overhead > benefit at this size |
| Juniors learning | Tutor mode (GOTCHA variant) | Builds knowledge, not just code |
| Postmortems | Short GOTCHA template | 90min instead of 2 days |
Notice what is missing: no rule says “always do SDD” or “always do ATLAS”. The only “always” is always ask first — what is the bottleneck?
This is the most uncomfortable lesson of this series. Tools are tools. Pick them per task, not per identity.
TEMPLATE
Framework selector — use this before every non-trivial task:
# Quick framework check
1. Will this take > 4 hours OR touch > 5 files?
→ If yes, consider SDD (small spec, 20-40 lines)
2. Is this an AI task I will run 3+ times this month?
→ If yes, consider GOTCHA (versioned prompt in repo)
3. Does this cross teams, disciplines, or include handoffs?
→ If yes, consider ATLAS (at least the Architect step)
4. Is the on-call engineer likely to see this in production
at 2am within a quarter?
→ If yes, add a learning note (Article 4 technique)
Zero "yes" answers → skip all frameworks. Just write the code.Rule of thumb: if you are adding a framework because “the book says so”, stop. Frameworks justify their cost only when they remove friction you can measure.
CHALLENGE
Look at your last 20 PRs. For each one, ask: which framework actually helped, and which was overhead? Be honest. If more than 50% of the frameworks you applied did not make the PR better, you are over-frameworking. Cut one this week.
In the final article, we put everything together — DORA metrics plus AI-specific metrics, the full playbook, and the templates in one place. The honest version of “continuous improvement in the AI era”.
→ Article 6: Your AI-Native DevOps Playbook (coming soon)
If this series helps you, consider sponsoring me on GitHub or buying me a coffee.
This is part 5 of 6 in the series “The Three Ways in the AI Era”. Previous: Continuous Learning When AI Writes Half Your Code.
Loading comments...