The Three Ways in the AI Era -- Parte 5
SDD, ATLAS, GOTCHA: cuándo usar cuál (y cuándo fallan todos)
Tras cuatro artículos, SDD, ATLAS y GOTCHA parecen magia. Las specs arreglan el flujo. GOTCHA arregla el feedback. El modo tutor arregla el aprendizaje. Elige la herramienta, aplícala, entrega mejor código.
Esa es la mitad de la verdad. La otra mitad es que ninguno de estos frameworks es una bala de plata, y los equipos que apilan los tres sin pensar se vuelven más lentos, no más rápidos. Este artículo es la parte incómoda. Dónde brilla cada framework, dónde falla, y qué hacer cuando el bottleneck real no es algo que un framework pueda arreglar.
El Problema

Trabajé con un equipo el año pasado que adoptó SDD, ATLAS y GOTCHA en el mismo trimestre. El fundador había leído los libros. El CTO había visto las charlas en conferencias. Todo el mundo estaba entusiasmado.
Tres meses después:
- Cada PR exigía una spec, un review con prompt GOTCHA y un checklist ATLAS. La edad media de PR pasó de 1 día a 5.
- Los devs dedicaban el 20% de su semana a escribir specs de 200 líneas para cambios de CSS de 10 líneas.
- El repo tenía 17 prompts GOTCHA distintos. La mitad se contradecían. Nadie era dueño de ninguno.
- Las ceremonias de “Architect” de ATLAS bloqueaban cada lunes 90 minutos a un sprint de 3 personas.
El equipo hacía “best practice” de manual. Su output se derrumbó.
He visto el mismo patrón en un banco, en una scale-up y en una consultoría. Los frameworks no eran el problema. Aplicarlos a cada tarea era el problema.
El Primer Principio de Gene Kim dice: lotes pequeños. Dosis pequeñas, también. Un framework es una herramienta, no una religión.
La Solución
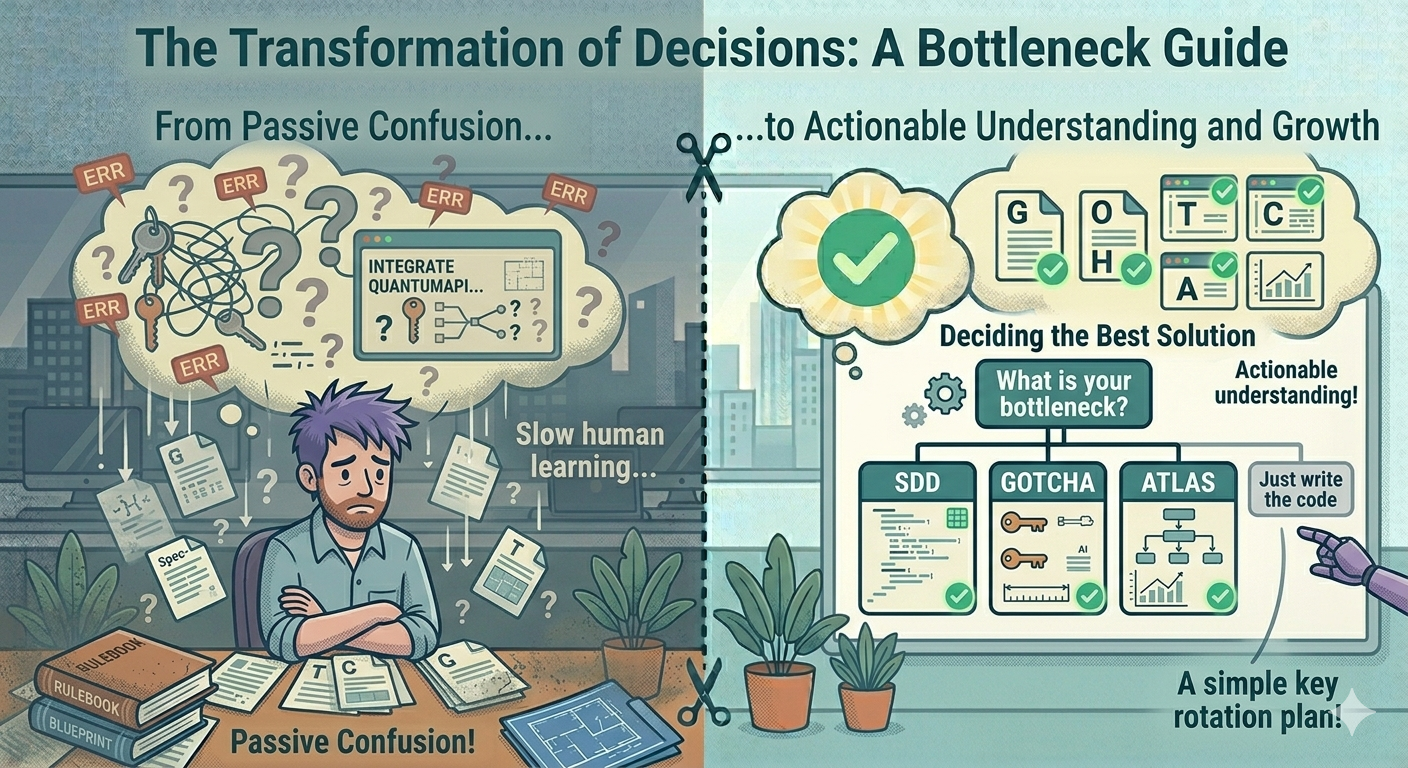
Antes de añadir cualquier framework, haz una pregunta:
¿Cuál es nuestro bottleneck real ahora mismo?
No “¿qué podría salir mal?”. No “¿qué usan otros equipos?”. Qué está ralentizando a nuestro equipo, este mes, de forma medible. Responde eso primero. Luego elige el framework que encaja. O ninguno.
Aquí está el mapa:
| Bottleneck | SDD | GOTCHA | ATLAS |
|---|---|---|---|
| PRs demasiado grandes / scope creep | ✅ Principal | ⚠️ Indirecto | ⚠️ El paso Architect ayuda |
| Ruido del reviewer IA / feedback ignorado | ⚠️ Ayuda a acotar scope | ✅ Principal | ❌ Capa equivocada |
| Equipo no alineado / handoffs se caen | ❌ Demasiado estrecho | ❌ Demasiado estrecho | ✅ Principal |
| Conocimiento no cuaja (bus factor 0) | ⚠️ Las specs ayudan | ✅ Tutor mode + learning notes | ⚠️ El paso de handoff ayuda |
| Equipo pequeño, app simple | ❌ Exagerado | ⚠️ Solo para tareas repetitivas | ❌ Exagerado |
Tres frameworks. No uno. El arte está en saber cuál.
Ejecutar
SDD — cuándo brilla, cuándo falla
Brilla en:
- Features con criterios de aceptación claros
- Trabajo dirigido por compliance (auditorías, regulaciones, seguridad)
- Equipos nuevos en IA que necesitan guardarraíles
- Cualquier cosa donde el scope creep sea el patrón
Falla en:
- Spikes exploratorios — aún no sabes la respuesta, no finjas que sí
- Bug fixes de menos de 30 minutos
- Refactors pequeños
- Tweaks puros de UI
Anti-patrón — “Spec ceremony”: escribir una spec de 200 líneas con Goals, Non-goals y Criterios de Aceptación para un cambio de CSS de 10 líneas. Vi a un equipo desperdiciar el 20% de la capacidad de sprint en esto antes de que alguien dijera “arregla el margen ya”.
Caso real: Un equipo fintech exigía specs para cada PR. Su bug fix de 2 líneas para un off-by-one tardó 4 días porque la spec la tenían que revisar dos seniors, luego el código, luego la learning note. El mismo bug se habría arreglado en 20 minutos sin SDD.
GOTCHA — cuándo brilla, cuándo falla
Brilla en:
- Tareas repetitivas de IA: code review, resúmenes de PR, triage de incidentes, borradores de postmortem
- Dominios de alto riesgo (seguridad, finanzas, PQC) donde el contexto importa
- Cualquier tarea de IA que el equipo ejecuta más de dos veces por semana
Falla en:
- Tareas creativas de una sola vez
- Exploración temprana (“¿qué opciones tenemos siquiera?”)
- Sesiones de pair programming improvisadas
- Cualquier cosa donde el prompt tenga que cambiar cada vez
Anti-patrón — “Prompt fossilization”: un repo con 17 prompts GOTCHA, la mitad contradictorios, ninguno con dueño. Nadie los lee. La IA sigue el que le apuntas por último. El output se vuelve aleatorio.
Caso real: Una consultoría construyó una librería de 23 prompts GOTCHA para sus clientes. Después de 6 meses, tres decían a la IA “nunca marques problemas de estilo” y otros dos decían “aplica siempre las guías de estilo”. Las reviews se volvieron inconsistentes, los devs perdieron confianza, la librería se descartó y se reconstruyó desde 4 prompts bien mantenidos.
ATLAS — cuándo brilla, cuándo falla
Brilla en:
- Iniciativas grandes cross-funcionales (varios equipos, varias disciplinas)
- Trabajo con handoffs reales (backend → frontend → ops)
- Features que duran un trimestre, no una semana
Falla en:
- Tareas de dev individual
- Startups con 2-5 ingenieros (overhead > beneficio)
- Trabajo de ciclo corto donde “Architect” tarda más que la tarea
Anti-patrón — “Checklist theater”: los devs marcan las cajas de ATLAS sin pensar. El paso Architect se rellena con boilerplate. Trace se salta. Stress-test es “sí, compila”. El ritual existe. El pensamiento no.
Caso real: Una startup de 3 personas adoptó ATLAS después de que su CTO volviera de una conferencia. Cada PR exigía un write-up completo de ATLAS incluyendo Link, Assemble y Stress-test. En un mes, las PRs tenían una edad media de 2 días y los devs se reían del proceso abiertamente. Tiraron ATLAS entero. Dos años después, recuperaron solo el paso “Architect”, para features más largas que un sprint.
La verdad incómoda — los tres pueden fallar juntos

Si tu bottleneck real es cultural — falta de confianza, falta de ownership, falta de cultura de aprendizaje, liderazgo que castiga errores — ningún framework lo va a arreglar.
Los frameworks son amplificadores. Hacen que los equipos buenos sean mejores. Hacen que los equipos que ya sufren sean dolorosamente lentos y sigan sufriendo. SDD en un equipo que no confía en sus devs se convierte en un mecanismo de gatekeeping. GOTCHA en un equipo sin cultura de code review se convierte en 17 prompts contradictorios. ATLAS en un equipo que no habla se convierte en 90 minutos de silencio por semana.
El anti-patrón más grande es “Framework tower”: un equipo usando SDD + ATLAS + GOTCHA + DORA + BDD + TDD + DDD + SAFe. Cada uno tenía sentido por separado. Apilados, no entregan nada. He visto a una empresa en Serie C dedicar 6 meses a “mejora de procesos” y entregar dos features.
Si nada se está rompiendo, no añadas un framework. El aburrimiento no es razón para añadir proceso.
Cómo usa el equipo de QuantumAPI los frameworks de verdad

Tras 3 meses, el equipo de los Artículos 1-4 dejó de seguir los frameworks al pie de la letra y empezó a encajarlos con el trabajo real:
| Tipo de tarea | Qué usan | Por qué |
|---|---|---|
| Feature ≥ 4 horas O ≥ 5 archivos | SDD (spec completa) | El scope creep era el dolor real |
| Bug fix pequeño | Escribir el código directo | Overhead de SDD > impacto del bug |
| Cualquier tarea IA recurrente | Prompt GOTCHA, versionado en el repo | La consistencia importa aquí |
| Chat IA de una sola vez | Prompt plano, sin GOTCHA | Creatividad, no reproducibilidad |
| Feature nueva cruzando 2+ equipos | Solo el paso Architect de ATLAS | Alineación sin ceremonia |
| Trabajo a escala de sprint | Saltarse ATLAS entero | Overhead > beneficio a este tamaño |
| Juniors aprendiendo | Modo tutor (variante GOTCHA) | Construye conocimiento, no solo código |
| Postmortems | Template corto GOTCHA | 90 min en vez de 2 días |
Fíjate en lo que falta: ninguna regla dice “haz siempre SDD” o “haz siempre ATLAS”. El único “siempre” es preguntar siempre primero — ¿cuál es el bottleneck?
Esta es la lección más incómoda de la serie. Las herramientas son herramientas. Elígelas por tarea, no por identidad.
Plantilla
Selector de framework — úsalo antes de cada tarea no trivial:
# Check rápido de framework
1. ¿Esto tardará > 4 horas O tocará > 5 archivos?
→ Si sí, considera SDD (spec pequeña, 20-40 líneas)
2. ¿Es una tarea IA que voy a ejecutar 3+ veces este mes?
→ Si sí, considera GOTCHA (prompt versionado en el repo)
3. ¿Cruza equipos, disciplinas o incluye handoffs?
→ Si sí, considera ATLAS (al menos el paso Architect)
4. ¿Es probable que el ingeniero de guardia vea esto
en producción a las 2am dentro del trimestre?
→ Si sí, añade una learning note (técnica del Artículo 4)
Cero "sí" → sáltate todos los frameworks. Solo escribe el código.Regla del pulgar: si estás añadiendo un framework porque “lo dice el libro”, para. Los frameworks solo justifican su coste cuando eliminan fricción que puedes medir.
El Reto
Mira tus últimas 20 PRs. Para cada una, pregúntate: ¿qué framework ayudó de verdad y cuál fue overhead? Sé honesto. Si más del 50% de los frameworks que aplicaste no mejoraron la PR, estás sobre-frameworking. Quita uno esta semana.
En el artículo final juntamos todo — métricas DORA más métricas específicas de IA, el playbook completo y las plantillas en un solo sitio. La versión honesta de “mejora continua en la era de la IA”.
→ Artículo 6: Tu playbook de DevOps nativo para IA (próximamente)
Si esta serie te ayuda, considera patrocinarme en GitHub o invitarme a un café.
Esta es la parte 5 de 6 de la serie “Los Tres Principios en la Era de la IA”. Anterior: Aprendizaje continuo cuando la IA escribe la mitad de tu código.
Loading comments...