The Three Ways in the AI Era -- Part 2
Specs Before Code: Why AI Needs SDD to Keep Batches Small
Last article we watched a team produce a 47-file pull request in 45 minutes. The reviewer closed the tab. The PR sat for 6 days. The First Way — Flow, small batches — was broken.
This article is about fixing it. Same team, same task, one big change: they write a spec before they write a prompt. The batch drops from 47 files to 5. Lead time from 6 days to 1. And the humans stay in charge.
PROBLEM

The problem is not the AI. The problem is what we hand it.
In the last article, the senior dev typed one sentence into Copilot Chat:
“Integrate QuantumAPI into our API and frontend. We need encryption at rest and signed responses.”
That is a prompt. It is not a spec. It has no boundaries, no acceptance criteria, no list of things the AI should not touch. So the AI filled every empty space with code. Auth middleware. Retry policies. Docker base images. React components. 47 files of “helpful” suggestions.
Gene Kim wrote in 2016 that batch size is the single strongest predictor of lead time. Small batches = fast flow. Big batches = chaos. Ten years later, DORA’s State of DevOps Report confirms it every year. The math has not changed. Only the tools have.
AI tools default to big batches. They want to be helpful. Ask for a cup of water, they deliver a bathtub. Unless you give them boundaries, they fill every bit of unused space with more code.
That is what SDD fixes.
SOLUTION
SDD — Spec-Driven Development — is the idea that the spec is the source of truth, not the code. You write what the system should do, what it should not do, and how you will know it is done. Then you hand the spec to the AI. The code becomes the output, not the input.
This is not a new idea. Dan North was writing BDD specs in 2006. Waterfall had functional specs. What changed is that LLMs make specs actually useful — because now the spec is the input to code generation, not a document that collects dust in Confluence.
Two tools are pushing SDD hard right now:
- GitHub Spec Kit — open source, CLI-based, works with Copilot, Claude, and Gemini
- AWS Kiro — a full IDE built around specs
Both share the same structure. A good spec has 5 parts:
| Part | What it answers |
|---|---|
| Goal | Why does this exist? What problem does it solve? |
| Scope | What is in? One feature, small surface area. |
| Non-goals | What is explicitly not in? This is the critical part. |
| Acceptance criteria | How do we know it is done? Testable checklist. |
| Constraints | Tech stack, deadlines, dependencies, guardrails. |
A quick comparison with what we did in Article 1:
| Prompt (Article 1) | Spec (this article) |
|---|---|
| “Integrate QuantumAPI into our API and frontend” | Encrypt 3 PII fields on UserProfile at rest. Scope: UserProfile entity only. Non-goals: auth, UI, retry. Acceptance: round-trip test passes, no endpoint shape changes. Constraints: .NET 10, EF Core 10, QuantumAPI SDK v2.3. PR ≤ 8 files. |
Where does ATLAS fit? SDD tells you what goes in the spec. ATLAS — especially the Architect and Trace steps — tells you how to validate the spec is actually good before handing it to the AI. No hidden assumptions, no scope creep, no un-traced dependencies. The human owns the spec. The AI owns the code.
EXECUTE
Our QuantumAPI team is back. Same mission: encrypt sensitive fields, sign API responses, rotate keys every 90 days. Same 8-week deadline. This time with SDD.
Step 1 — Decompose the big ask
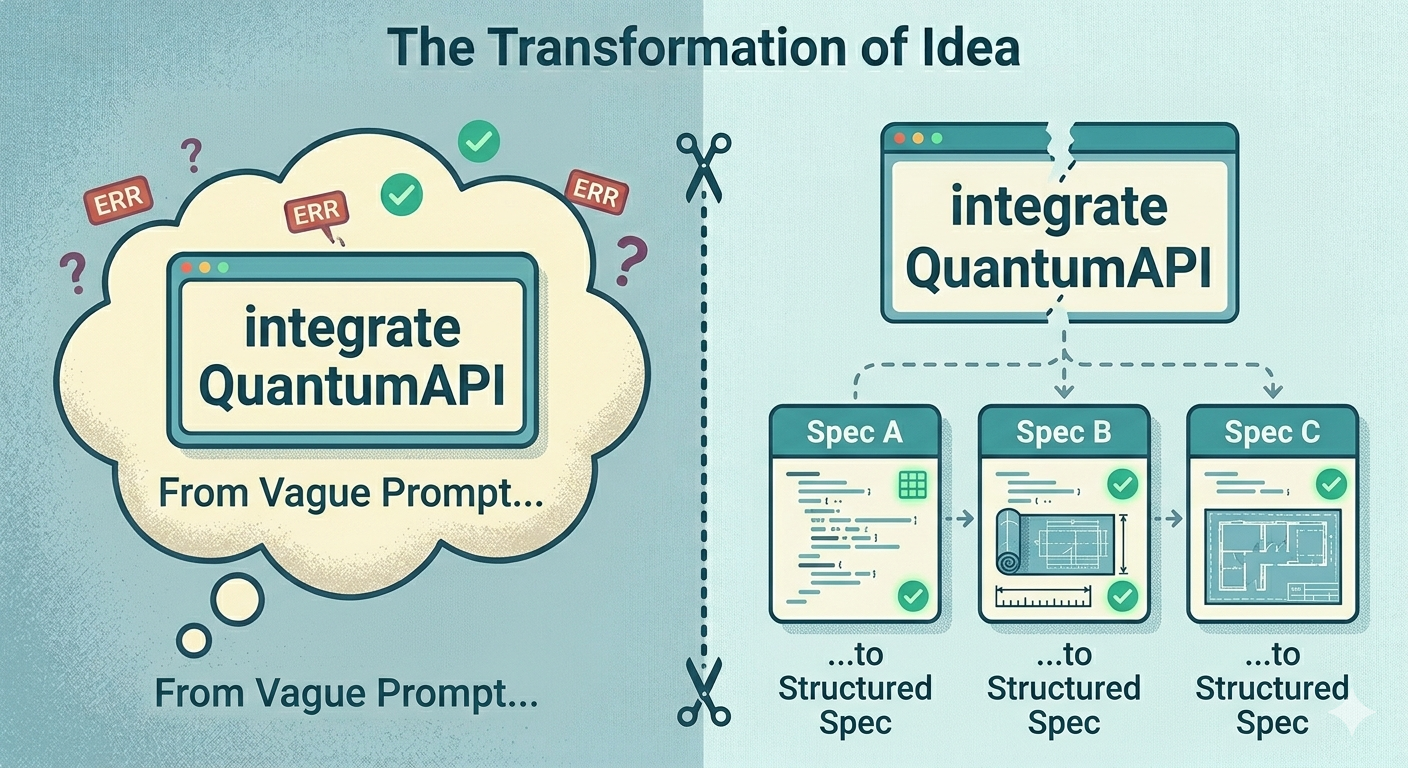
The team runs ATLAS’s Architect step on the ask: “Can this be done as one PR?” Answer: no. Three separate concerns. So they split it:
- Spec A: Encrypt sensitive fields at rest
- Spec B: Sign API responses with ML-DSA
- Spec C: Automatic key rotation
Three specs. Three PRs. Reviewable separately. Mergeable independently. The 47-file monster is already dead on paper.
Step 2 — Write Spec A
They initialise Spec Kit in the repo. Pin a version tag (check the Spec Kit releases for the latest):
uvx --from git+https://github.com/github/spec-kit.git@vX.Y.Z specify init <project>This drops a .specify/ folder with templates. They write Spec A as specs/001-encrypt-pii/spec.md:
# Spec 001: Encrypt sensitive fields at rest
## Goal
Encrypt 3 fields (email, phone, nationalId) on UserProfile and 2 fields
(iban, accountHolder) on Transaction before writing to PostgreSQL.
Decryption happens transparently on read. Compliance audit in 8 weeks
requires field-level encryption for PII.
## Scope
- New service class `IFieldEncryptor` + implementation `QuantumApiFieldEncryptor`
- EF Core value converters wired on the 5 fields above only
- Configuration binding for QuantumAPI endpoint and vault ID
- Unit tests for the encryptor
- One integration test: write a UserProfile, read it back, assert
original values are returned
## Non-goals
- NO changes to authentication or authorization
- NO changes to UI or React components
- NO retry policies (may be added in a future spec if needed)
- NO key rotation (that is Spec C)
- NO response signing (that is Spec B)
- NO changes to other entities (Portfolio, Position, Order, etc.)
- NO new endpoints; existing endpoints must behave identically
## Acceptance criteria
- [ ] `IFieldEncryptor` interface with `EncryptAsync` and `DecryptAsync`
- [ ] `QuantumApiFieldEncryptor` uses the official QuantumAPI .NET SDK v2.3
- [ ] EF Core value converters applied on exactly the 5 fields listed
- [ ] Round-trip test: write/read returns original plaintext
- [ ] Existing `GET /users/{id}` returns the same JSON shape as before
- [ ] No secrets in appsettings.json; vault ID via environment variable
- [ ] `dotnet build` and `dotnet test` pass
- [ ] PR touches ≤ 8 files
## Constraints
- .NET 10, EF Core 10
- QuantumAPI .NET SDK v2.3 (already in Directory.Packages.props)
- PostgreSQL 16 (no schema change; fields stay as `text`)
- Azure DevOps CI must stay green
- Deadline: merge by Friday
## Open questions
- None. All decisions above are locked.40 lines. Takes 20 minutes to write. Saves days of rework.
Step 3 — Feed the spec to the AI
Using Spec Kit’s slash commands inside their AI assistant:
/specify @specs/001-encrypt-pii/spec.md
/plan
/tasks
/implementOr, without Spec Kit, the same idea as a plain prompt:
“Implement the spec at
specs/001-encrypt-pii/spec.md. Do not add anything outside the scope. Do not change files not listed in the acceptance criteria. If a decision is not in the spec, stop and ask.”
The AI produces a PR with 5 files:
src/Domain/IFieldEncryptor.cssrc/Infrastructure/QuantumApiFieldEncryptor.cssrc/Infrastructure/Data/QuantumEncryptedConverter.cssrc/Infrastructure/Data/ApplicationDbContext.cs(only entity config changes)tests/Infrastructure.Tests/QuantumApiFieldEncryptorTests.cs
A snippet of the generated QuantumApiFieldEncryptor:
public class QuantumApiFieldEncryptor(
IQuantumApiClient client,
IOptions<QuantumApiOptions> options) : IFieldEncryptor
{
public async Task<string> EncryptAsync(string plaintext, CancellationToken ct)
{
var result = await client.Vault
.EncryptAsync(options.Value.VaultId, plaintext, ct);
return result.Ciphertext;
}
public async Task<string> DecryptAsync(string ciphertext, CancellationToken ct)
{
var result = await client.Vault
.DecryptAsync(options.Value.VaultId, ciphertext, ct);
return result.Plaintext;
}
}Clean. Single responsibility. Does exactly what the spec says. Nothing else.
Step 4 — Result
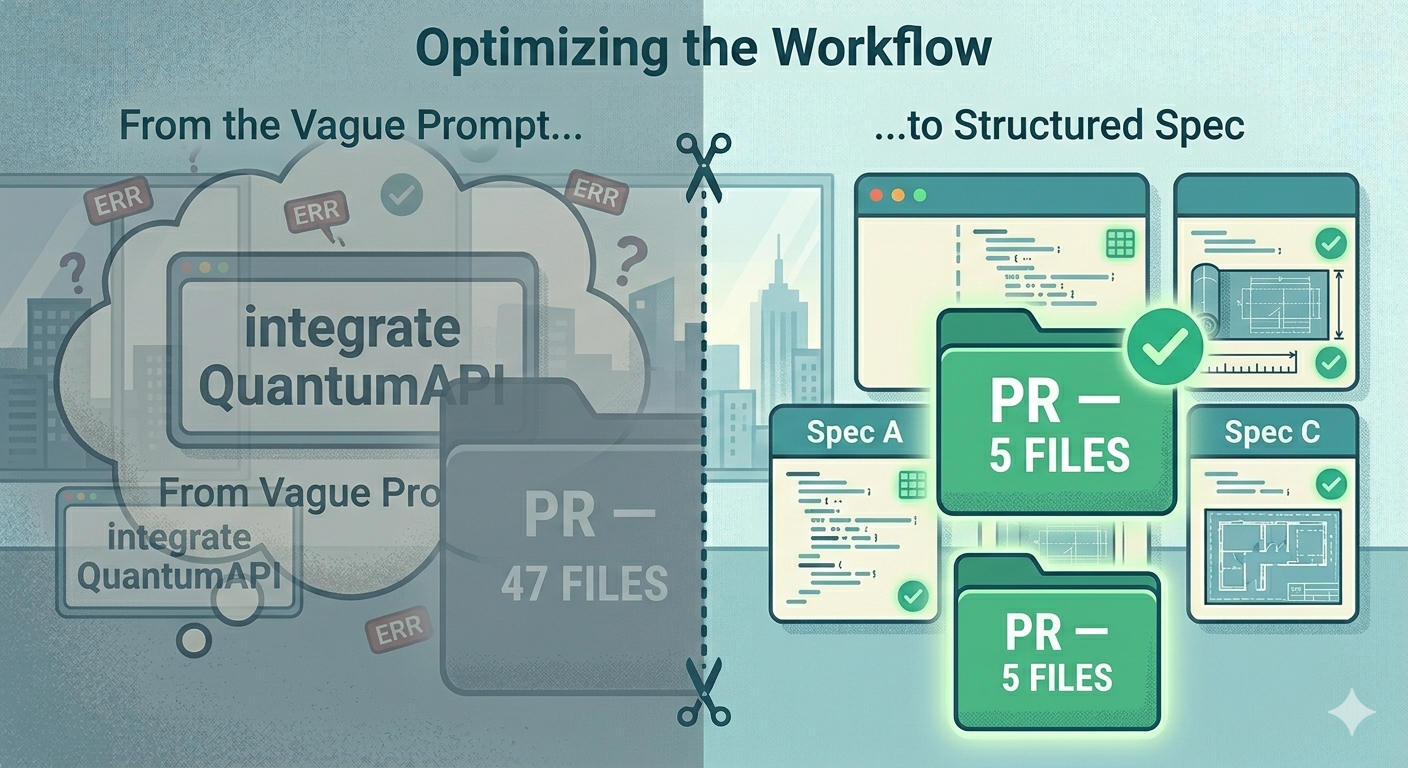
| Metric | Article 1 (no spec) | Article 2 (with SDD) |
|---|---|---|
| Files changed | 47 | 5 |
| Review time | reviewer gave up | 8 minutes |
| Lead time | 6 days | 1 day |
| Scope creep | auth, retry, Docker, UI | none |
| Bus factor | 0 | 3 (everyone can read the spec) |
The team repeats the process for Spec B (signing) and Spec C (rotation). Three small PRs over two weeks. All mergeable. All reviewable. All traceable back to a spec a human wrote and owned.
First Way restored. Small batches. Visible work. No big handoffs.
TEMPLATE
Here is the minimal spec template. Copy, paste, fill in. Save to specs/XXX-feature-name/spec.md.
# Spec XXX: <short feature name>
## Goal
<1-3 sentences. The why. Link to the business reason.>
## Scope
- <what is in — keep small>
## Non-goals
- <what is NOT in — this is where specs win>
## Acceptance criteria
- [ ] <testable outcome 1>
- [ ] <testable outcome 2>
## Constraints
- <tech, deadlines, dependencies>
## Open questions
- <if any — otherwise write "None">Rule of thumb: if your spec is under 15 lines, it is probably too vague. If it is over 100 lines, you have scoped too much — split it into two specs.
CHALLENGE
This week, pick the next AI-assisted task on your backlog. Before you open Copilot or Claude, write the spec. Limit: one page of markdown. Then feed the spec to the AI and measure your PR size. Compare it to your usual AI-generated PRs.
In the next article we tackle the Second Way — Feedback. Our team got the batch size right with SDD. But then the AI reviewer left 22 comments on the clean 5-file PR. 19 were noise. We will fix that with GOTCHA.
→ Article 3: AI Code Review That Doesn’t Cry Wolf (coming soon)
If this series helps you, consider sponsoring me on GitHub or buying me a coffee.
This is part 2 of 6 in the series “The Three Ways in the AI Era”. Previous: The DevOps Handbook Turns 10.
Loading comments...