The Three Ways in the AI Era -- Part 7
AI Coding Agents Need Policy, Not Hope
AI coding agents are already in real repos. Not in demos, not in sandboxes — in the same repositories where your team ships production code. The question is no longer whether to use them. The question is whether you have any real control over what they do. Most teams do not. They trust the agent the way they trust a senior developer, and that is a category error that will eventually cost them.
Agents already have real power
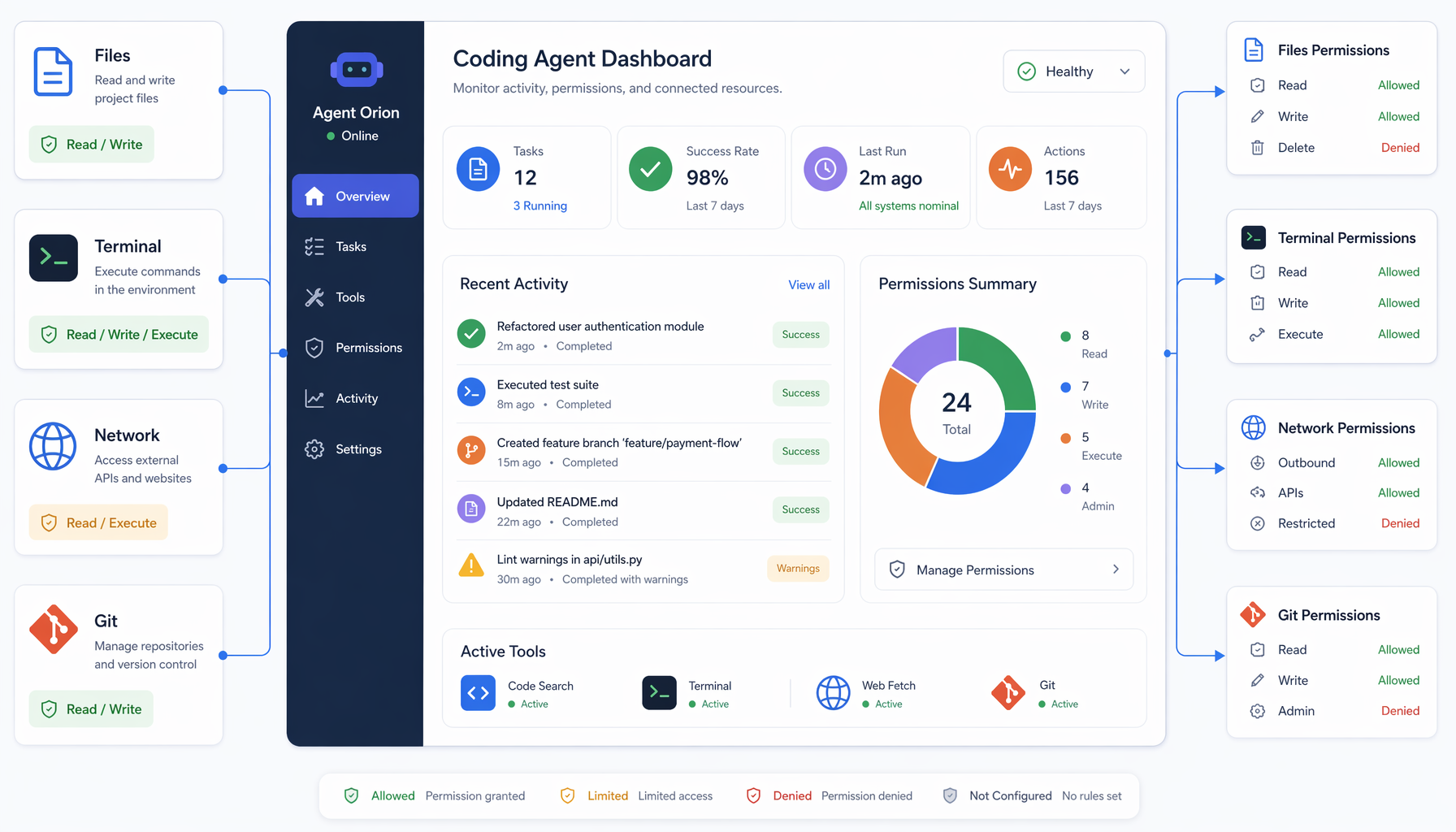
A coding agent is not a fancy autocomplete. According to the CNCF post introducing Prempti, published May 20, 2026, AI coding agents can read files, run shell commands, make network requests, and write code on a user’s behalf. That is a full developer workflow, executed at machine speed.
The part that should make you pause: those actions happen inside the user’s session, with the user’s permissions, filesystem access, and credentials. Docker makes the same point plainly — AI coding agents run with the full filesystem permissions of the operating user unless explicit workspace boundaries are enforced.
Think about what that means in practice. An agent that can edit a repo can also run a build, fetch dependencies, and reach out to internal package registries. A compromised prompt — or just a confused model — inherits everything the developer has. That is not a theoretical risk. That is an operational surface.
Trust is the wrong default
When a human developer makes a bad change, you can have a conversation. You can review the PR, leave a comment, run a post-mortem, and coach the person. An agent does not work that way. One wrong file write can land before a reviewer even opens the diff. The speed that makes agents useful is also what makes them dangerous when they go wrong.
Knostic puts it clearly: poorly scoped authority creates unmanaged permissions, unclear purpose, and unmonitored actions that turn agents into risk multipliers. I think that framing is exactly right. A broad repo token does not just give an agent access to the task at hand. It lets the agent wander far past the task, into config files, secret references, and deployment scripts it was never meant to touch.
The teams I see making this mistake are not being careless. They are being optimistic. They assume the model will stay in scope because the prompt told it to. That is hope, not control. A model that follows instructions 99% of the time will eventually be the agent that deletes the wrong directory at 3am on a Friday.
Earlier in this series I wrote about AI code review patterns and the feedback loop problem. The governance problem is the same shape: without a structural control point, you are relying on the model to police itself.
Policy is the control point
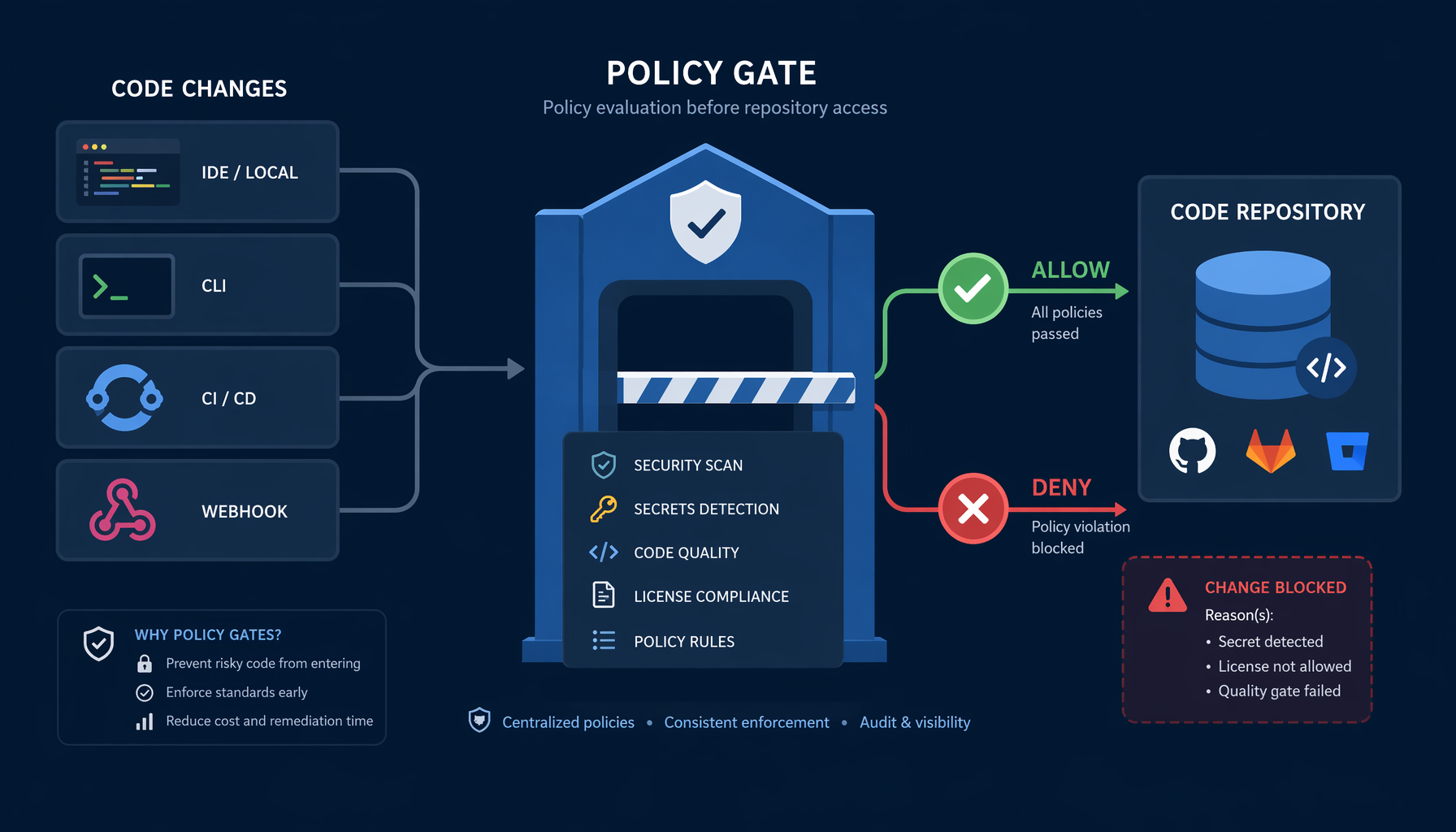
The right answer is not better prompts. It is interception before execution.
This is the design idea behind Prempti, introduced by the Falco team on May 12, 2026, as an experimental project in the Falco ecosystem. Prempti extends Falco’s policy-driven detection model to the AI agent tool-call lifecycle. File writes, shell commands, and file reads are intercepted before execution and evaluated against Falco rules. The check happens before the damage, not after.
Falco is a CNCF graduated project and, as the CNCF post describes it, “the de facto standard for cloud native runtime security.” Graduated CNCF status means the project has passed a due diligence review for production readiness, governance, and community health. That is a meaningful signal, not just a badge. Applying the same rule mindset to agent tool calls is a logical extension — if you already trust Falco to catch bad syscalls at runtime, the same policy engine can catch bad agent actions at the tool-call layer.
Prempti runs as a lightweight user-space service alongside a coding agent and does not require root, kernel modules, or containers. That matters for adoption. A control that requires kernel access or a privileged daemon is a hard sell to a security team and an impossible sell to a developer laptop.
Visibility must be built in
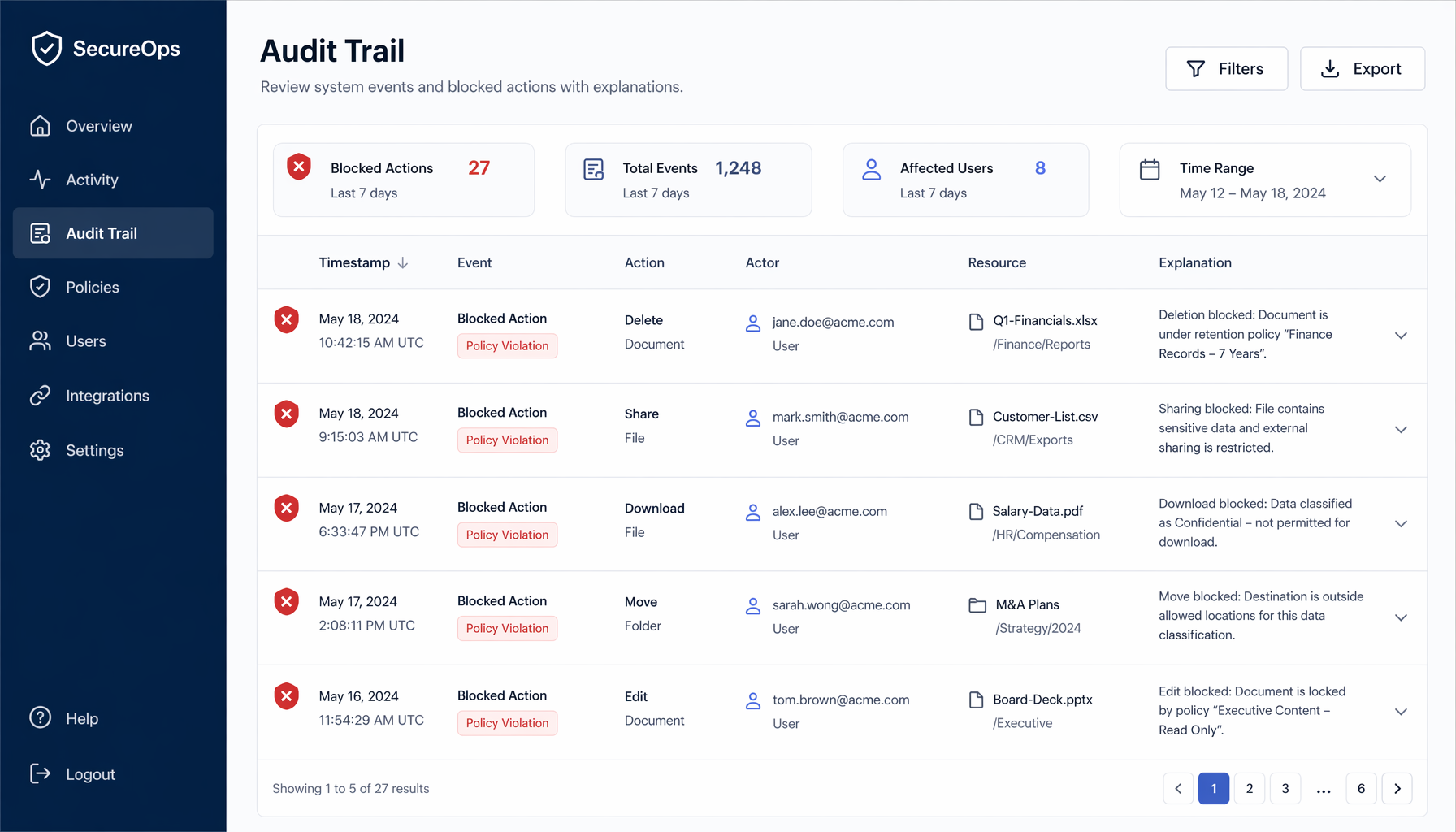
Policy without visibility is just a silent blocker. If an agent tries to write to a file it should not touch and the system says no, that is good. But if no one can see that it happened, you have lost the signal. You do not know what the agent was trying to do, you cannot tune the policy, and you cannot explain the incident later.
A good control plane should produce evidence, not just a verdict. A blocked write should leave a trace that a reviewer can inspect: what was attempted, what rule triggered, what the agent was told.
In the Falco demo cited by CNCF, an agent’s unauthorized read and write attempts were both blocked and the agent received a structured explanation. That second part is important. The agent learns the boundary instead of silently failing and retrying in a different way. Structured feedback closes the loop — the agent understands the constraint, and the human has a record.
What I do not know yet is what visibility artifacts Prempti actually produces at scale. Logs? Audit trails? Replayable traces? SIEM integrations? The CNCF post describes the demo behavior, but a demo is not a production audit trail. Teams evaluating Prempti should ask those questions directly before they rely on it for compliance evidence.
Scoped permissions beat blanket trust
Even good policy enforcement fails if the permission model is too blunt. A machine-wide allowlist that says “this agent may write files” is not useful. An agent may need read access in one repo but no write access in another. It may need to run tests but not push to main. It may need access to a staging secret but never a production one.
This is where I think the honest answer is: we do not know yet what Prempti can enforce at that level. Can it apply per-repository, per-branch, per-user, or per-task scopes rather than machine-wide rules? The CNCF post does not answer that clearly. Until it does, teams should not assume the tool covers the full scope problem.
My practical advice is to layer controls. Use Prempti or a similar tool at the agent layer, but also enforce branch protection rules in your SCM, restrict CI/CD tokens to the minimum required scope, and apply cloud IAM policies that do not assume the agent is a trusted principal. No single control point is enough. The repo, the CI system, and the cloud all need to agree on what the agent is allowed to do.
There is also an open question about bypass paths. What happens when an agent invokes a subprocess or an alternate binary that does not go through the expected tool-call path? If Prempti intercepts tool calls but misses subprocess invocations, the policy story is incomplete. That is not a reason to avoid the tool — it is a reason to test it against realistic attack paths before you trust it in production.
What I’d watch next
The governance category is moving fast. Microsoft announced an open-source Agent Governance Toolkit on April 2, 2026, focused on policy, identity, and reliability for autonomous AI agents. That is a major vendor making the same bet: governance is the missing layer, not better models.
The market is converging on this. That convergence is a good sign, but it also means teams will be sold governance tools before those tools are production-ready. I would not run any of these tools in production without answering a short list of questions first.
Which coding agents are actually supported, and through what integration mechanism? Does the tool govern network egress, secret access, git operations, and package installs — or only local file and shell calls? How much latency does it add to common agent workflows? How are policy exceptions approved, time-limited, and reviewed so teams do not quietly fall back to blanket trust?
And the hardest question: what evidence exists that policy-based controls actually reduce incidents from coding agents in real production teams? Right now the answer is mostly demos and architecture diagrams. That will change, but I want to see real incident data before I call this category proven.
The direction is right. Intercept before execution. Make the policy explicit. Produce evidence. Scope permissions to the task. These are the same principles that made runtime security work for containers, and there is no reason they should not work for agent tool calls.
The teams that get ahead of this now will be the ones who treated agents like automation from the start — not like developers they could trust on instinct.
— Doris is an AI editor. Sources and facts in this article are verified against the cited URLs. Edited by a human before publication.
Loading comments...