AI in Production -- Parte 4
El Problema del Coste: Cómo Mantener Tu Factura de IA Predecible
El Problema
Alguien de tu equipo abre la factura del cloud. Ve la línea de IA. Se queda mirándola. Y te la reenvía con un signo de interrogación.
Esto pasa más de lo que la gente habla en público. Las APIs de IA cobran por token — una unidad que equivale más o menos a cuatro caracteres de texto. Suena pequeño. Se acumula rápido, y lo hace de formas difíciles de predecir.
La cosa con los tokens: pagas por los dos lados de la conversación. Pagas por lo que envías (tokens de prompt) y por lo que recibes (tokens de completion). Tu system prompt, la entrada del usuario, cualquier contexto que inyectes, el historial de la conversación — todo cuenta. Un system prompt que parece tener 200 palabras son unos 250 tokens. Envíalo en cada petición, a 15€ por millón de tokens, a 10.000 usuarios al día — eso son 37,50€ solo por el system prompt. Antes de que el usuario pregunte nada.
El verdadero problema es la imprevisibilidad. Puedes estimar tu línea base. Lo que no puedes predecir es:
- Un usuario que pega un documento de 50 páginas en la entrada
- Un bug que incluye sin querer el historial completo de la conversación en cada turno
- Una nueva feature que duplica la longitud del prompt sin que nadie se dé cuenta
- Un crecimiento de tráfico que no habías presupuestado

El coste en sistemas de IA tiene una propiedad que la mayoría de servicios no tienen: escala con la complejidad de la entrada, no solo con el volumen de peticiones. Dos peticiones pueden costar 20 veces diferente dependiendo de lo que contienen. El auto-scaling estándar y las alertas de presupuesto diseñadas para costes uniformes por petición no funcionan bien aquí.
Necesitas diseñar para el coste desde el principio. No como una optimización posterior — desde el principio.
Las Cuatro Palancas

1. Límites de entrada. El control más simple y más efectivo. Limita cuántos tokens puede enviar un usuario por petición. Rechaza las entradas demasiado grandes antes de que lleguen a la IA. Esto previene los peores escenarios y obliga a los usuarios a ser específicos.
2. Caching. Muchas peticiones de IA son repetitivas. Chatbots de FAQ, resúmenes de documentos, explicaciones de código — los usuarios suelen hacer las mismas preguntas o muy parecidas. Cachea las respuestas. No pagues dos veces por la misma respuesta.
3. Routing de modelos. No necesitas tu modelo más potente (y más caro) para cada tarea. Clasifica las peticiones por complejidad y enruta las simples a modelos más baratos. Esto puede reducir los costes un 80% con la carga de trabajo adecuada.
4. Rate limiting por usuario. Un solo usuario pesado no debería consumir todo tu presupuesto. Establece límites por usuario o por tenant. Avísales cuando se acerquen al límite en vez de cortarles sin aviso.
Ejecución
1. Límites de entrada — rechaza antes de pagar
Valida el tamaño de la entrada antes de llamar a la IA. La mayoría de proveedores facturan por tokens reales, así que parar las peticiones demasiado grandes en la puerta es gratis.
Una estimación rápida de tokens: 1 token ≈ 4 caracteres de texto en inglés. No es exacto, pero es suficiente para un límite de protección.
public class TokenGuard
{
// Rough character-to-token ratio for English text
private const double CharsPerToken = 4.0;
public static int EstimateTokens(string text) =>
(int)Math.Ceiling(text.Length / CharsPerToken);
public static bool ExceedsLimit(string text, int maxTokens) =>
EstimateTokens(text) > maxTokens;
}Úsalo en el punto de entrada de cada llamada a la IA:
public async Task<string?> SummarizeAsync(
string text,
CancellationToken cancellationToken = default)
{
const int MaxInputTokens = 2000; // ~8000 characters
if (TokenGuard.ExceedsLimit(text, MaxInputTokens))
{
// Log it — this is useful cost data
_logger.LogWarning(
"Input rejected: estimated {Tokens} tokens exceeds limit of {Limit}",
TokenGuard.EstimateTokens(text), MaxInputTokens);
// Return null — caller shows "input too long" message
return null;
}
// ... proceed with AI call
}Devuelve un tipo de resultado específico si necesitas que el llamador distinga entre “IA no disponible” y “entrada rechazada”:
public enum SummarizeStatus { Ok, InputTooLong, AiUnavailable }
public record SummarizeResult(string? Summary, SummarizeStatus Status);2. Caching — no pagues dos veces
IDistributedCache de .NET te da una abstracción de cache que funciona con Redis, SQL Server o en memoria — mismo código sin importar el backend.
using Microsoft.Extensions.Caching.Distributed;
using System.Security.Cryptography;
using System.Text;
using System.Text.Json;
public class CachedAiSummaryService : IAiSummaryService
{
private readonly IAiSummaryService _inner;
private readonly IDistributedCache _cache;
private readonly ILogger<CachedAiSummaryService> _logger;
// Cache summaries for 1 hour — adjust based on how often content changes
private static readonly DistributedCacheEntryOptions CacheOptions = new()
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromHours(1)
};
public CachedAiSummaryService(
IAiSummaryService inner,
IDistributedCache cache,
ILogger<CachedAiSummaryService> logger)
{
_inner = inner;
_cache = cache;
_logger = logger;
}
public async Task<string?> SummarizeAsync(
string text,
CancellationToken cancellationToken = default)
{
var cacheKey = BuildCacheKey(text);
// Check cache first
var cached = await _cache.GetStringAsync(cacheKey, cancellationToken);
if (cached is not null)
{
_logger.LogDebug("Cache hit for summary key {Key}", cacheKey[..8]);
return cached;
}
// Cache miss — call the AI
var result = await _inner.SummarizeAsync(text, cancellationToken);
// Only cache successful, non-empty responses
if (!string.IsNullOrWhiteSpace(result))
{
await _cache.SetStringAsync(cacheKey, result, CacheOptions, cancellationToken);
}
return result;
}
private static string BuildCacheKey(string text)
{
// Hash the input so the key is a fixed size
var hash = SHA256.HashData(Encoding.UTF8.GetBytes(text));
return $"ai:summary:{Convert.ToHexString(hash)}";
}
}Regístralo como decorator en Program.cs:
// Register the real service
builder.Services.AddScoped<AiSummaryService>();
// Register the cached decorator as the interface
builder.Services.AddScoped<IAiSummaryService>(sp =>
new CachedAiSummaryService(
sp.GetRequiredService<AiSummaryService>(),
sp.GetRequiredService<IDistributedCache>(),
sp.GetRequiredService<ILogger<CachedAiSummaryService>>()));
// Redis for distributed cache (replace with AddDistributedMemoryCache() for local dev)
builder.Services.AddStackExchangeRedisCache(options =>
{
options.Configuration = builder.Configuration.GetConnectionString("Redis");
});3. Routing de modelos — la herramienta adecuada para cada tarea
No todas las peticiones necesitan tu mejor modelo. Un clasificador que responde sí/no, una respuesta que solo reformatea texto, una tarea de extracción simple — no necesitan el mismo modelo que un análisis complejo.
Define niveles basándote en tu carga de trabajo real:
public enum RequestComplexity { Simple, Standard, Complex }
public static class ComplexityClassifier
{
public static RequestComplexity Classify(string text)
{
var estimatedTokens = TokenGuard.EstimateTokens(text);
// Simple: short, likely a lookup or reformatting
if (estimatedTokens < 200) return RequestComplexity.Simple;
// Complex: long document, likely needs reasoning
if (estimatedTokens > 1500) return RequestComplexity.Complex;
return RequestComplexity.Standard;
}
}Luego enruta a diferentes configuraciones de modelo:
public class RoutedAiSummaryService : IAiSummaryService
{
private readonly IConfiguration _config;
private readonly IHttpClientFactory _factory;
public async Task<string?> SummarizeAsync(
string text,
CancellationToken cancellationToken = default)
{
var complexity = ComplexityClassifier.Classify(text);
// Use config to keep model names out of code
var modelKey = complexity switch
{
RequestComplexity.Simple => "Ai:Models:Simple",
RequestComplexity.Complex => "Ai:Models:Complex",
_ => "Ai:Models:Standard"
};
var model = _config[modelKey]
?? throw new InvalidOperationException($"{modelKey} is required.");
// Use the selected model for this request
return await CallAiAsync(text, model, cancellationToken);
}
// ... implementation
}En appsettings.json:
{
"Ai": {
"Models": {
"Simple": "gpt-5-mini",
"Standard": "gpt-5",
"Complex": "gpt-5"
}
}
}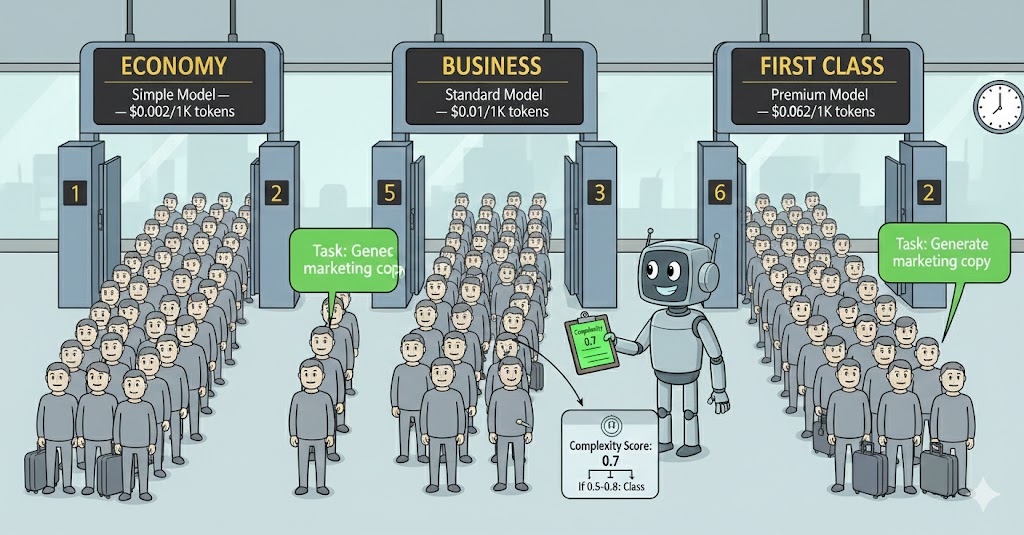
Una carga de trabajo típica se divide más o menos 60/30/10 entre simple/standard/complex. Si tu modelo más barato cuesta 20 veces menos que el premium, enrutar el 60% del tráfico hacia él reduce tu factura de forma significativa.
Yendo más allá: routing semántico. El routing por complejidad es un buen punto de partida, pero solo mira la longitud de la petición. Un enfoque más potente es añadir un pre-procesador — un clasificador rápido y barato que evalúa la petición y la enruta basándose tanto en la complejidad como en la especialización del dominio.
Por ejemplo, podrías tener:
- Un modelo especializado en código para peticiones que implican generación o depuración de código
- Un modelo afinado en texto legal o de cumplimiento para análisis de contratos
- Un modelo de propósito general para todo lo demás
El pre-procesador es en sí una llamada de IA — y sí, también tiene un coste. Estás añadiendo un paso de clasificación en cada petición. La apuesta es que este coste pequeño y consistente es menor que el ahorro de enrutar correctamente. Un modelo pequeño al que le preguntas “¿qué tipo de petición es esta?” es mucho más barato por token que un modelo frontier de propósito general, y si enruta el 40% de tu tráfico a un modelo especializado que rinde mejor y cuesta menos, las cuentas suelen salir. Pero mídelo — no lo asumas. Añade el coste del clasificador a tus métricas de ai.tokens.prompt y haz seguimiento del panorama completo.
public enum RequestDomain { Code, Legal, General }
public static class DomainClassifier
{
// Fast, cheap call to a small classifier model
public static async Task<RequestDomain> ClassifyAsync(
string text,
ISmallClassifierClient classifier,
CancellationToken ct = default)
{
var domain = await classifier.ClassifyAsync(text, ct);
return domain switch
{
"code" => RequestDomain.Code,
"legal" => RequestDomain.Legal,
_ => RequestDomain.General
};
}
}Entonces tu router combina ambas dimensiones:
var complexity = ComplexityClassifier.Classify(text);
var domain = await DomainClassifier.ClassifyAsync(text, _classifier, ct);
var modelKey = (complexity, domain) switch
{
(RequestComplexity.Simple, _) => "Ai:Models:Simple",
(_, RequestDomain.Code) => "Ai:Models:Code",
(_, RequestDomain.Legal) => "Ai:Models:Legal",
(RequestComplexity.Complex, RequestDomain.General) => "Ai:Models:Complex",
_ => "Ai:Models:Standard"
};Esto es más complejo de mantener — necesitas monitorizar cada modelo de forma independiente y mantener el clasificador preciso. Merece la pena a escala, pero empieza con routing solo por complejidad y añade routing por dominio solo cuando tengas datos que muestren qué dominios existen en tu tráfico real.
4. Rate limiting por usuario
No dejes que un solo usuario consuma todo tu presupuesto. El rate limiting en la capa de IA es diferente del rate limiting de API — estás controlando coste, no solo tráfico.
public class RateLimitedAiSummaryService : IAiSummaryService
{
private readonly IAiSummaryService _inner;
private readonly IDistributedCache _cache;
// Max AI calls per user per hour
private const int MaxCallsPerHour = 20;
public async Task<string?> SummarizeAsync(
string text,
string userId, // Pass userId from the calling context
CancellationToken cancellationToken = default)
{
var key = $"ai:ratelimit:{userId}:{DateTime.UtcNow:yyyyMMddHH}";
var countStr = await _cache.GetStringAsync(key, cancellationToken);
var count = countStr is null ? 0 : int.Parse(countStr);
if (count >= MaxCallsPerHour)
{
_logger.LogWarning("Rate limit hit for user {UserId}", userId);
return null; // Caller shows "you've reached your limit" message
}
// Increment counter with 2-hour expiry (covers the current + next hour slot)
await _cache.SetStringAsync(
key,
(count + 1).ToString(),
new DistributedCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromHours(2)
},
cancellationToken);
return await _inner.SummarizeAsync(text, cancellationToken);
}
}Qué medir
Del artículo 3, ya estás registrando ai.tokens.prompt y ai.tokens.completion. Añade estos:
- Coste por petición — calcula a partir del conteo de tokens x precio del modelo. Regístralo. Alerta si el total diario cruza un umbral de presupuesto.
- Tasa de aciertos de cache —
cache_hits / (cache_hits + cache_misses). Una tasa por debajo del 20% en una carga de trabajo estable significa que tu estrategia de caching necesita revisión. - Tasa de rechazo de entrada — con qué frecuencia se rechazan peticiones por tamaño. Tasas altas pueden significar que tu límite es demasiado agresivo o que tu UX no lo comunica bien.
- Distribución de modelos — qué porcentaje de peticiones va a cada nivel de modelo. Esto te dice si tu routing funciona.
Checklist
- ¿Hay un límite de tokens en las entradas de los usuarios? ¿Qué pasa cuando se supera?
- ¿Estás cacheando respuestas para peticiones repetidas o similares?
- ¿Usas diferentes modelos para diferentes niveles de complejidad?
- ¿Hay un rate limit por usuario o por tenant?
- ¿Tienes una métrica de coste diario con un umbral de alerta?
- ¿Puedes explicarle a Finanzas qué hace que la factura de IA suba o baje?
La última pregunta es la prueba real. Si no puedes explicarlo, no puedes controlarlo.
Antes del Siguiente Artículo
Has cubierto disponibilidad, observabilidad y coste. Tu sistema es resiliente, visible y controlado en presupuesto.
Ahora alguien de Legal se acerca. Han oído hablar de la funcionalidad de IA. Quieren saber: ¿qué datos le envías al modelo? ¿Quién los almacena? ¿Durante cuánto tiempo? ¿Pueden los usuarios darse de baja? ¿Alguno de esos datos es personal según el GDPR?
Eso es el artículo 5.
Si esta serie te resulta útil, puedes invitarme a un café.
Este es el artículo 4 de la serie AI in Production. Siguiente: Governance y Compliance — lo que Legal te va a preguntar antes de que tu funcionalidad de IA salga a producción, y cómo diseñar para ello desde el principio.
Loading comments...